

In zwei Wochen soll die neue Website live gehen? Dann sollte man nicht darauf vertrauen, dass die Web-Entwickler schon alles richtig gemacht haben. Mit den richtigen Tools kann man die typischen Fehler effizient finden.
 Im Rahmen eines Relaunch-Projektes kommt irgendwann kurz vor dem Go-Live der Punkt, an dem der Stage (also z. B. neu.meinewebsite.de) einen finalen Stand erreicht hat. Bevor die Website live gestellt wird, sollte man aber in jedem Fall noch umfangreiche Tests vornehmen, um sicherzustellen, dass der Relaunch gute Ergebnisse bringen wird.
Im Rahmen eines Relaunch-Projektes kommt irgendwann kurz vor dem Go-Live der Punkt, an dem der Stage (also z. B. neu.meinewebsite.de) einen finalen Stand erreicht hat. Bevor die Website live gestellt wird, sollte man aber in jedem Fall noch umfangreiche Tests vornehmen, um sicherzustellen, dass der Relaunch gute Ergebnisse bringen wird.
Da fast immer Problemfelder bei der Überprüfung der Website gefunden werden, sollte der Check hinreichend früh vor dem Go-Live erfolgen, sodass nötige Änderungen noch umgesetzt werden können. Am Anfang eines Relaunch-Projektes sollte auch der Aspekt „Showstopper“ geklärt worden sein: Ist es möglich, den Go-Live noch zu verschieben, wenn es aus SEO-Sicht Probleme gibt, die den Live-Gang der Website nicht empfehlenswert machen?
Idealerweise ist der Stage nur per „Noindex“ für Suchmaschinen gesperrt (siehe suchradar Ausgabe 64), sodass alle gängigen Tools problemlos auf die neue Website zugreifen können – aber ohne dass Google diese auch indexieren würde.
301
Der wichtigste Punkt beim Check vor dem Go-Live ist sicherlich die Überprüfung der 301-Umleitungen. Wie und mit welchen Tools das gemacht werden kann, wurde bereits ausführlich behandelt (suchradar Ausgabe 65).
Dennoch soll auch an dieser Stelle noch einmal explizit darauf hingewiesen werden: Ein Go-Live ohne Überprüfung der 301-Umleitung birgt ein extrem hohes Risiko, da gerade bei den Umleitungen oft Fehler gemacht werden.
Rendering prüfen
Darüber hinaus gibt es aber noch andere Aspekte, die beim Pre-Launch-Check extrem wichtig sind. Dazu gehört auch das Prüfen des Renderings. Bereits seit einigen Jahren ist Google in der Lage, eine Website zu „rendern“, also die Seiten unter Zuhilfenahme von CSS- und JavaScript-Dateien sowie Bildern, Fonts und anderen Ressourcen wie in einem Browser darzustellen. Google „weiß“ also, wo sich eine Überschrift befindet, ob Text sichtbar ist und wie hoch der Anteil an Werbeflächen ist.
In den Google-Richtlinien (https://support.google.com/webmasters/answer/35769?hl=de) steht eindeutig:
„Damit Google die Inhalte Ihrer Website vollständig interpretieren kann, lassen Sie zu, dass alle Assets Ihrer Website gecrawlt werden, die das Rendern der Seite wesentlich beeinflussen können. Dazu zählen z. B. CSS- und JavaScript-Dateien, die die Interpretation der Seiten beeinflussen.“
Manchmal passiert es bei Relaunch-Projekten, dass Assets, die für das Rendering wichtig sind, per robots.txt gesperrt werden. Aber es kann auch andere Fälle geben, in denen Google nicht in der Lage ist, die Seite korrekt zu rendern, was dann zu realen Ranking-Nachteilen führen kann.
Ob Google eine Seite rendern kann, muss in der Google Search Console geprüft werden. Dafür muss der Stage natürlich erstmal dort als Property angelegt werden. Wenn die Website per „Noindex“ gesperrt ist, ist das problemlos möglich und führt auch nicht dazu, dass die Website indexiert wird.
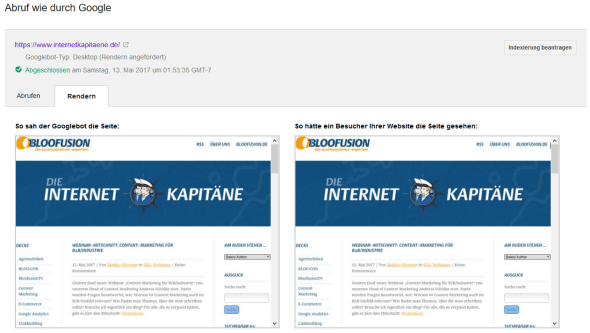
Über den Punkt „Abruf wie durch Google“ kann man dann einzelne Seiten prüfen. Es empfiehlt sich, dort pro Seitentyp eine einzelne Seite zu prüfen (also z. B. die Startseite, eine Rubrikenseite, eine Produktseite, eine Blog-Seite …). Das sollte jeweils für beide mögliche Endgeräte („Desktop“ und „Smartphone“) gemacht werden – mit dem positiven Nebeneffekt, dass man faktisch auch gleichzeitig die Mobiltauglichkeit der Website überprüft.
Das Ergebnis muss man dann in zweierlei Hinsicht kontrollieren. Zunächst sollte man sicherstellen, dass die beiden Sichtweisen, die das Tool liefert (siehe Abbildung 1), möglichst übereinstimmen: „So sah der Googlebot die Seite“ und „So hätte ein Besucher Ihrer Website die Seite gesehen“ sollten also faktisch nicht voneinander abweichen.
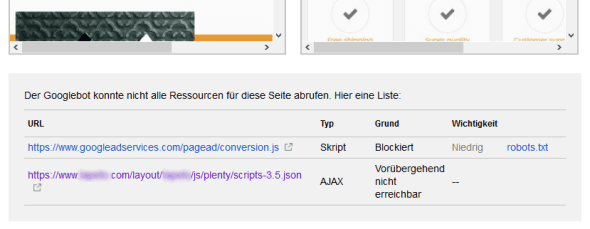
Unterhalb dieser Darstellung erhält man manchmal eine Liste mit Assets, auf die Google zum Rendern zugreifen wollte, die aber für Google nicht erreichbar waren. Hier muss man zwei Fälle unterscheiden:
- Wenn eine Ressource als „Vorübergehend nicht erreichbar“ bezeichnet wird, sollte man den gesamten Check für diese Seite und dieses Endgerät einfach nochmal neu durchführen. Es passiert manchmal, dass Google auf bestimmte Ressourcen nicht zugreifen kann, obwohl diese nicht gesperrt sind. Um ein komplettes Bild zu erhalten, sollten aber alle nicht gesperrten Ressourcen in das Rendern einbezogen werden. Deswegen muss man das dann einfach wiederholen.
- Falls eine Ressource als „Blockiert“ bezeichnet wird, muss man sich fragen, ob die Ressource für das Rendern relevant ist. In der Regel erkennt Google (siehe die Spalte „Wichtigkeit“) sehr gut, ob diese Ressource wirklich relevant ist (siehe Abbildung 2). Wenn ein Asset für das Rendern benötigt wird (Bilder, Fonts …), sollte man diese auch für Suchmaschinen freigeben; Tracking-Skripte können aber durchaus gesperrt werden, da diese das Rendern nicht beeinflussen.
Der große Crawl
Mit dem Tool Screaming Frog SEO Spider ist es kostenlos (bis 500 URLs) bzw. kostenpflichtig (>500 URLs) möglich, eine Website zu crawlen. Das Tool beginnt dabei – wenn man den „Mode“ „Spider“ wählt – auf einer bestimmten Seite (meistens: Startseite) und folgt dann allen Links.
Wenn das Tool durchgelaufen ist, sollte man also ein Abbild dessen haben, was Google bei seinen Crawls auch findet. Das stimmt so in der Praxis nicht unbedingt, weil Google auch URLs einfach mal „rät“, diese über JavaScript-Dateien zusammenbastelt oder aus externen Verlinkungen heranzieht. All das macht der Screaming Frog SEO Spider nicht, sodass man hier einen „sauberen Crawl“ erhält. In der Regel ist das für die typischen Zwecke auch vollkommen ausreichend.
Es sei noch gesagt, dass es natürlich auch andere Tools gibt, mit denen man eine Website crawlen und anschließend analysieren kann. Gerade webbasierte Tools wie Onpage.org oder DeepCrawl erfreuen sich zunehmender Beliebtheit – auch, weil sie die Ergebnisse in der Regel schöner aufbereiten und zum Teil noch wichtige Informationen für SEO-Einsteiger mitliefern.
Im Folgenden werden die wichtigsten Aspekte genannt, die man bei einem Crawl überprüfen sollte. Je nach Anforderung kann ein Test natürlich deutlich darüber hinausgehen.
Übrigens: Wenn der Stage für Suchmaschinen gesperrt wird, indem alle Seiten ein Robots-Meta-Tag „noindex“ enthalten, kann man natürlich nicht mehr prüfen, ob einzelne Seiten, die man später in der neuen Website per „noindex“ sperren möchte, dieses Tag auch wirklich enthalten. Das muss man in diesem Fall nach dem Go-Live machen – ebenso wie den Test, ob man das flächendeckende „noindex“ auch wirklich entfernt hat, weil das für die Website ja apokalyptische Effekte haben kann.
Und: Damit der Screaming Frog SEO Spider die Website überhaupt crawlen kann, muss man vorher die Option „Respect noindex“ ausschalten, da das Tool sich sonst vollkommen zu Recht weigert, auch nur eine einzige Seite anzuzeigen.
HTTP-Fehler
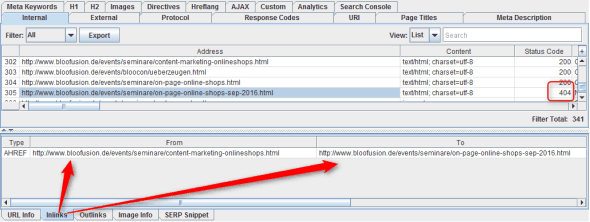
Im Idealfall sollten beim Crawling alle Seiten einen HTTP-Code („OK“) haben. Häufig gibt es aber auch interne Umleitungen (301) oder auch fehlerhafte Links (404 …). Optimal ist es mit Sicherheit, wenn man dem Ziel „100 % Code 200“ möglichst nahekommt.
Der Screaming Frog zeigt den HTTP-Code aller Seiten sehr zentral an. Um herauszufinden, wo z. B. auf eine 404-Seite verlinkt wird, klickt man auf den jeweiligen Link und wählt unten den Tab „Inlinks“ aus. Dort sieht man in der Spalte „From“, von welcher Seite aus auf die 404-Seite verlinkt wird.
Seitentiefe, Vollständigkeit der Inhalte
Es stellt sich auch die Frage, ob Google gut an alle Inhalte herankommt. Also: Gibt es Seiten, die innerhalb der Website nicht verlinkt sind, sodass Google diese nicht erreichen kann? Und gibt es Seiten, die zu tief sind und deswegen vielleicht gar nicht mehr indexiert werden?
Die zweite Frage ist leicht zu beantworten: Im Screaming Frog SEO Spider wird für jede Seite ein „Level“ ausgegeben, der die Klicktiefe angibt. Diese besagt, wie viele Link-Klicks – beginnend bei der Startseite – benötigt werden, um eine bestimmte Seite zu erreichen. Es gibt keinen allgemeingültigen Schwellwert, der besagt, ob eine Seite zu tief ist. Als Hausnummer kann man aber sicherlich sagen, dass die Klicktiefe nicht unbedingt zweistellig sein sollte. Übrigens: Damit die Klicktiefe korrekt berechnet ist, sollte auch die komplette Website gecrawlt werden.
Die Frage, ob Google alle Seiten innerhalb der Website erreichen kann, ist hingehen deutlich schwerer zu beantworten– man muss schließlich erst einmal eine bestimmte URL kennen, die eigentlich erreichbar sein sollte, um dann zu prüfen, ob diese auch beim Crawl gefunden wird. Typischerweise gibt es daher zwei Strategien:
- Man sollte grundsätzlich die eigene Website kritisch prüfen, ob es Formulare gibt, die den Zugang zu relevanten Inhalten steuern (z. B. „Archiv-Suche“). Häufig sind solche Funktionen dafür verantwortlich, dass Google an relevante Inhalte nicht herankommen kann. Zwar versucht Google immer mal wieder, Formulare auszufüllen, und prüft, welche Inhalte dann erscheinen. Aber darauf sollte man sich natürlich auf gar keinen Fall verlassen.
- Wer über eine Sitemap aller Inhalte verfügt, kann diese mit ein wenige Excel-Logik mit dem Crawl abgleichen. Idealerweise sollten alle Seiten aus der Sitemap in dem Crawl vollständig enthalten sein.
Irrelevante Seiten und URL-Parameter
Beim Crawl sollte auch geprüft werden, ob man bestimmte Seiten, die keinen Mehrwert bieten, für Suchmaschinen sperren sollte. Dazu gehören z. B.:
- Login-Seiten
- Vergleichsfunktionen
- Funktionen wie „Zur Liste hinzufügen“
- Druckversion
- Als PDF exportieren
- …
Falls man solche Seiten im Crawl findet, sollte man nach Möglichkeiten suchen, diese für Suchmaschinen zu sperren. Das kann entweder über die robots.txt oder über ein Robots-Meta-Tag „noindex“ erfolgen.
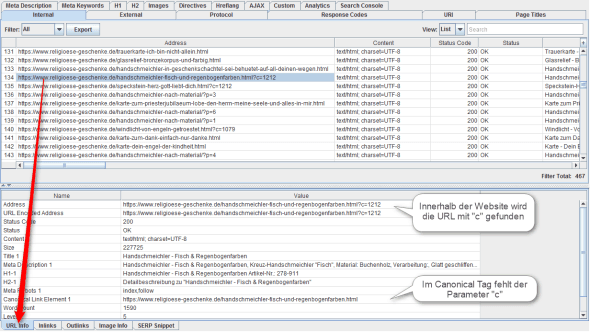
Ebenfalls wichtig ist die Suche nach irrelevanten URL-Parametern. Ein Beispiel findet sich in Abbildung 4: Das Shopsystem hängt den URLs der Produktdetailseiten einen Parameter „c“ an. Dieser Parameter ist aber irrelevant, wie das Canonical Tag, in dem der Parameter fehlt. Man muss natürlich prüfen, ob dies generell für einen bestimmten Parameter gilt.
Wenn man einen solchen irrelevanten Parameter identifiziert hat, sollte man ihn sich merken, um ihn später beim Go-Live in der Google Search Console („URL-Parameter“) einzutragen („URL-Parameter konfigurieren“).
Übrigens: Beim Screaming Frog SEO Spider kann man solche URL-Parameter ebenfalls eintragen, damit diese direkt aus der URL entfernt werden. So kann man dann einen zweiten Crawl durchführen und URLs so sehen, als gäbe es diese Parameter gar nicht. Unter „Configuration > URL Rewriting“ kann man im Tab „Remove Parameters“ diese Einstellung vornehmen.
Canonical Tags
Des Weiteren sollten unbedingt die Canonical Tags geprüft werden. Dafür ist es unerlässlich, vor dem Crawl die Option „Respect Canonical“ aus- und „Crawl Canonicals“ einzuschalten. Im Tab „Directives“ können dann verschiedene Reports abgerufen werden:
- „No Canonical“ zeigt Seiten auf, die kein Canonical Tag enthalten. Es kann schon mal passieren, dass die Tags bei einem bestimmten Seitentyp einfach vergessen wurden, sodass man diese entsprechend nachpflegen sollte.
- „Canonicalised“ listet Seiten auf, bei denen das Canonical Tag nicht der jeweiligen URL entspricht. Dafür kann es natürlich viele gute Gründe geben – streng genommen ist das Canonical Tag ja genau für solche Fälle da. Man sollte aber in jedem Fall prüfen, ob es nicht andere Möglichkeiten gibt, diese Dubletten zu realisieren (z. B. indem man einen URL-Parameter als irrelevant markiert).
hreflang-Tags
Wer eine internationale Website hat, sollte auch die hreflang-Tags überprüfen. Das kann der Screaming Frog SEO Spider seit Version 7 ebenfalls. Über den Tab „hreflang“ kann man hier verschiedene Reports erreichen, z. B. „Missing Self Reference“, wenn beim hreflang-Tag der Verweis auf die jeweilige Seite selbst fehlt.
Alternativ kann man auch externe Tools wie hreflang.ninja oder hreflang.org einsetzen, deren Ergebnis für manchen Nutzer vielleicht einfacher zu interpretieren ist.
Markup prüfen
Wer in seine Inhalte Markup eingebaut hat, sollte diese auch auf jeden Fall stichprobenweise überprüfen – eine der wenigen Funktionen, die der Screaming Frog SEO Spider nicht bietet. Dafür eignet sich das von Google bereitgestellte Tool „Test-Tool für strukturierte Daten“ (https://search.google.com/structured-data/testing-tool), das aber immer nur für eine einzelne URL funktioniert. Man sollte hier also unterschiedliche Seitentypen (Startseite, Produktdetailseite …) prüfen. Idealerweise zeigt das Tool die unterschiedlichen Markups mit dem Hinweis „0 Fehler, 0 Warnungen“ an.
HTTP/HTTPS-Probleme
Vor allem beim Wechsel von HTTP auf HTTPS im Rahmen eines Relaunches können viele Fehler passieren. So ist es nicht unüblich, dass z. B. die Canonical oder hreflang-Tags immer noch die HTTP-Version zeigen, während die Website selbst auf HTTPS wechselt. Viele dieser Fehler kann man relativ leicht identifizieren, indem man in den HTML-Code nach „http:“ sucht.
Der Screaming Frog SEO Spider bietet für diesen Zweck einen speziellen Report an: Mit „Insecure Content“ werden viele der typischen Fehler in einer langen Excel-Datei zusammengefasst. Alle möglichen Fehler kann aber auch dieser Report (z. B. das Laden von Fonts über HTTP in einer CSS-Datei) leider nicht finden.
Weitere Tests
Über den Screaming Frog SEO Spider können noch viel mehr Tests durchgeführt werden. Im Prinzip kann man dort alle sogenannten „Filter“ in den jeweiligen Tabs durchprobieren, um so z. B. fehlende Seitentitel („Page Titles“: „Missing“), überlange Meta Descriptions („Meta Descriptions“: „Over 156 characters“) oder fehlende Alt-Attribute bei Bildern („Images“: „Missing Alt Text“) zu finden.
Dabei muss man jeweils abwägen, ob eine bestimmte Änderung vor dem Go-Live wirklich noch sinnvoll ist, ob man diese nach dem Go-Live umsetzt oder es einfach lässt, wie es ist. Eine fehlende Meta Description oder ein zu langer Seitentitel ist zwar vielleicht „unschön“, in der Regel aber auch nicht unbedingt relevant. Bei einer fehlenden Meta Description greift Google einfach auf den Text der Seite zurück, um das Snippet zu bilden, was nicht unbedingt zu einem schlechten Ergebnis führen muss. Und zu lange Seitentitel schneidet Google einfach ab, was aber auch nicht nachteilig sein muss.
Hier sollte man also immer mit Augenmaß an die Sache herangehen, da es ja so kurz vor dem Go-Live primär darum geht, Fehler zu finden, die kritisch sind und die zu dramatischen Ranking-Verlusten führen können.
Fazit
Vor dem Go-Live der Website sollte die Website gründlich geprüft werden – am besten über einen Crawler wie den Screaming Frog SEO Spider. Damit kann man ein gutes Bild der Website aus Google-Sicht erzeugen. Aber auch die Google Search Console und das „Test-Tool für strukturierte Daten“ sind für den Pre-Launch-Check unabdingbare Werkzeuge, damit die Website beim Go-Live auch problemlos starten kann.
Dieser Beitrag ist in Ausgabe #66 des Magazins für SEO, SEA und E-Commerce „suchradar“ erschienen. Die gesamte Ausgabe #66 des suchradars mit dem Fokusthema „Online-Marketing für Start-ups: Erfolgreich starten, Fehler vermeiden“ kann unter www.suchradar.de kostenlos als PDF-Version heruntergeladen werden!

 SEO-Text – oder: Die Rolle von Content bei der Suchmaschinenoptimierung
SEO-Text – oder: Die Rolle von Content bei der Suchmaschinenoptimierung 6 Tipps für mehr Nutzer im eigenen Online-Shop
6 Tipps für mehr Nutzer im eigenen Online-Shop Die neue Google Search Console: Mehr Daten, neue Funktionen, alles gut?
Die neue Google Search Console: Mehr Daten, neue Funktionen, alles gut? SEO-Tipps für Online-Händler: So klappt das mit mehr organischem Traffic
SEO-Tipps für Online-Händler: So klappt das mit mehr organischem Traffic